2024年全国信息安全竞赛作品赛国家一等奖、最具创新创业价值奖
宋黄超、曹宝泉、陈一诚、钟宝仪

当前大模型在学术、新闻、作业、百科、文学等领域被广泛使用,为保障AIGC的合理使用,平台聚焦于学生作业、新闻媒体、文学小说、百科知识等,检测一段文本是否为大模型所生成,为维护信息的真实性提供了有力支持。

我们广泛收集多个场景数据进行模型训练,基于人类文本和AI文本的潜在特征分布差异,通过遮蔽扰动过程,设计文本鉴别的算法。项目基于人类文本和AI文本的潜在特征分布差异,通过大模型遮蔽扰动原始文本,计算原文本和扰动文本的特征差异,对输入文本进行鉴别。利用vivoBlueLM、Deepseek V2、T5系列等作为遮蔽模型,GPT2系列、Qwen2等作为基础模型,生成检测指标困惑度PPL、对数概率LL等基础特征和对数概率差DLL、score等衍生指标,最后根据检测指标通过支持向量机进行鉴别。平台引入OCR引擎支持多模态输入,并对中文文本定制处理方法实现对中文文本检测的支持。项目通过提高召回率来减少将人类文本误判为AI的错误,提高精确率来加大对AI文本的鉴别力度。
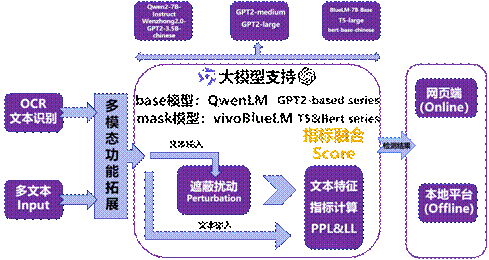
此外,项目采取并行计算和滑动窗口的算法,实现了高效计算输出和以句为单位的成分检测,为维护信息安全提供了有力支持。本项目帮助识别潜在的AI生成内容,有效维护了信息的真实性和可靠性。
针对大语言模型在学术论文、学生作业、新闻媒体、文学艺术、商品评论等领域的滥用,平台帮助识别潜在的AI生成内容,维护信息的真实性和可靠性,解决了AI生成文本检测时间长、准确率低的问题。