2023年全国信息安全竞赛作品赛国家三等奖
杨程瑜,唐嘉雄,刘禹锋,王玺源
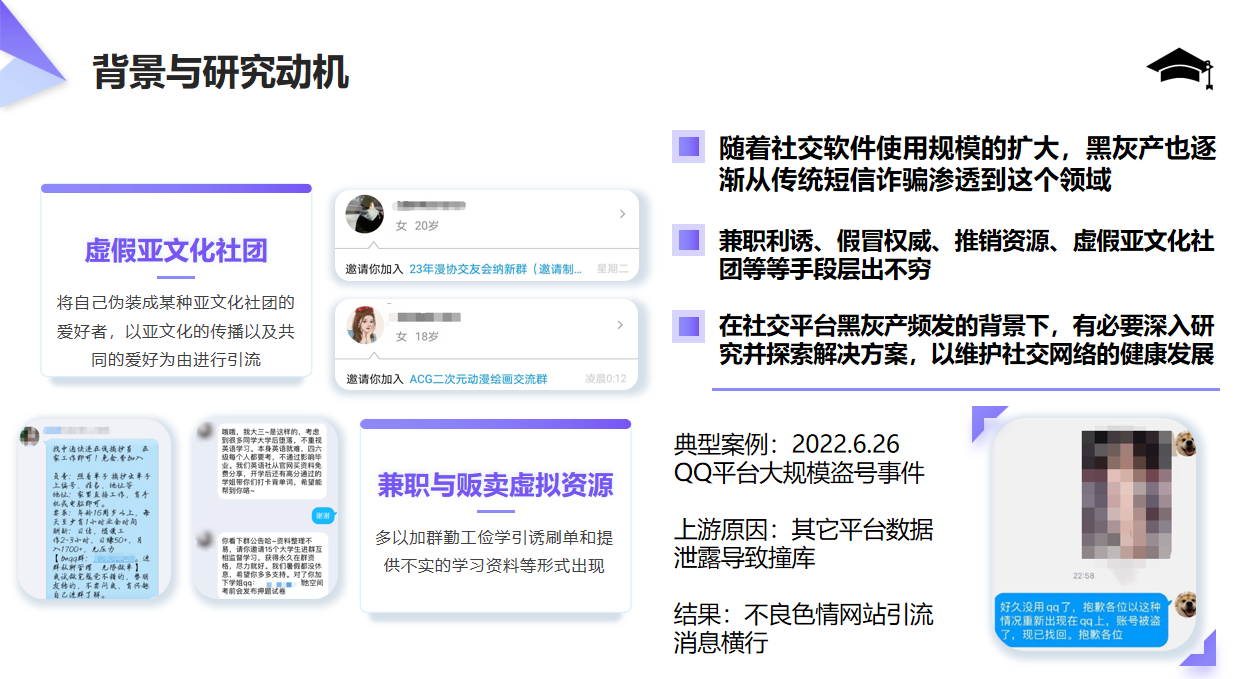
当今世界互联网高速发展,社交网络已经成为人们日常生活中不可或缺的一部分,为人们提供了方便快捷的交流和信息分享渠道。然而,随着社交网络的普及和使用规模的不断扩大,诈骗也逐渐从短信领域渗透到这个领域。社交网络诈骗频发的背景下,我们对这个新生领域产生了兴趣与想法,在探索优秀的解决方案中,我们提出了基于go-cqhttp的社交平台反诈风控机器人。
本作品主要有四个核心功能:1.生成社交网络2.生成超群网络3.诈骗文本分类模型4.时间序列检测算法。
我们根据消息序列的上下文互动来生成社交网络关系图,生成社交网络的意义是可以在群组中清晰的表现意见领袖类的用户。
我们根据两个群间重合人数的情况来生成超群网络图。超群网络图的一个主要功能是发现若干相近群聊中的主要群与次要群,以及它们之间的亲和力即关联有多大。当一个群聊内出现涉诈事件时,通过此超群网络图能够评估其它群的可能受到的威胁风险。

该算法的核心思想是,训练一个文本多分类神经网络,对可能的涉诈文本进行分类。即一条消息能够被该模型经过处理,然后给其打上标记,标明是否为涉诈消息。由于电信诈骗数据集和社交平台诈骗文本内容相似度不高,其效果不好。我们进行了约半年的数据收集工作,收集包含勤工俭学、兼职等字样的引流诈骗消息,约200条;从最近的20000条正常消息内容中分层抽样2000条。用该自制的数据集微调bert-base-chinese预训练模型,最后效果非常好。
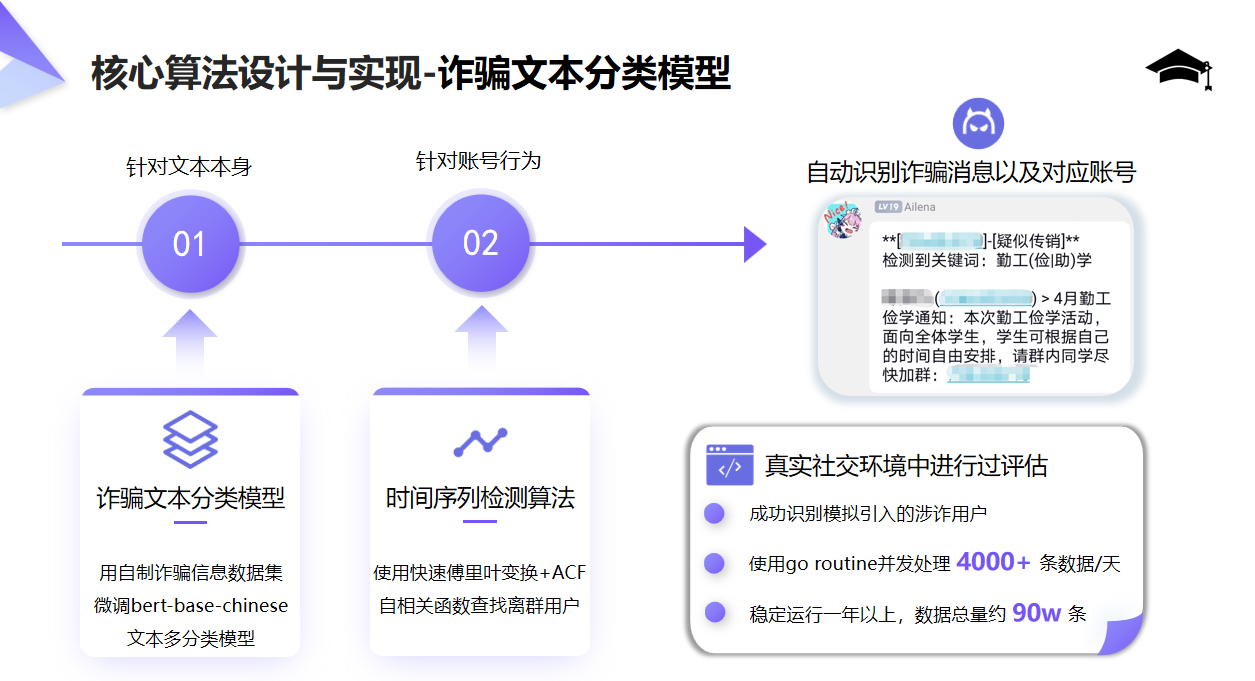
该算法的核心思想是,正常用户和涉诈脚本用户是两个群体,尤其在发言时间序列上会有偏离。正常用户常常单条消息长度较短、在聊天时短时间发送消息数量较多、同时和别的用户会有强烈的上下文消息交织。涉诈脚本用户往往每天固定时间,由脚本操控发送两三条比较长的引流消息。我们思考找出整个群聊用户群体时间序列的一个典型均值代表,用这个时间序列去和每个用户单独的时间序列进行求均方误差。然后求这些均方误差的均值和方差,能够构成一个正态分布。找出均方误差最大的用户,或者均方误差大于μ+2σ的用户,即视为离群用户。

总结来看,本作品通过一系列数据收集和数据处理,再加上FFT快速傅里叶变换+ACF自相关算法与BERT多分类模型,能够有效识别社交平台上的涉诈脚本账号。我们同时关注了涉诈脚本用户的发言内容和容易忽略的时间序列信息,多维度且有针对性的提出识别算法。并且开发前后端以及模型算法端,建立了一个完整的涉诈分析一体化系统。在真实环境中进行过测试,能够识别众多潜在涉诈用户。
详细作品内容可参考:http://forimoc.me/works/heimbot