2023年全国信息安全竞赛作品赛国家三等奖
赵海宁,庄赖宏,杭盖,张英豪
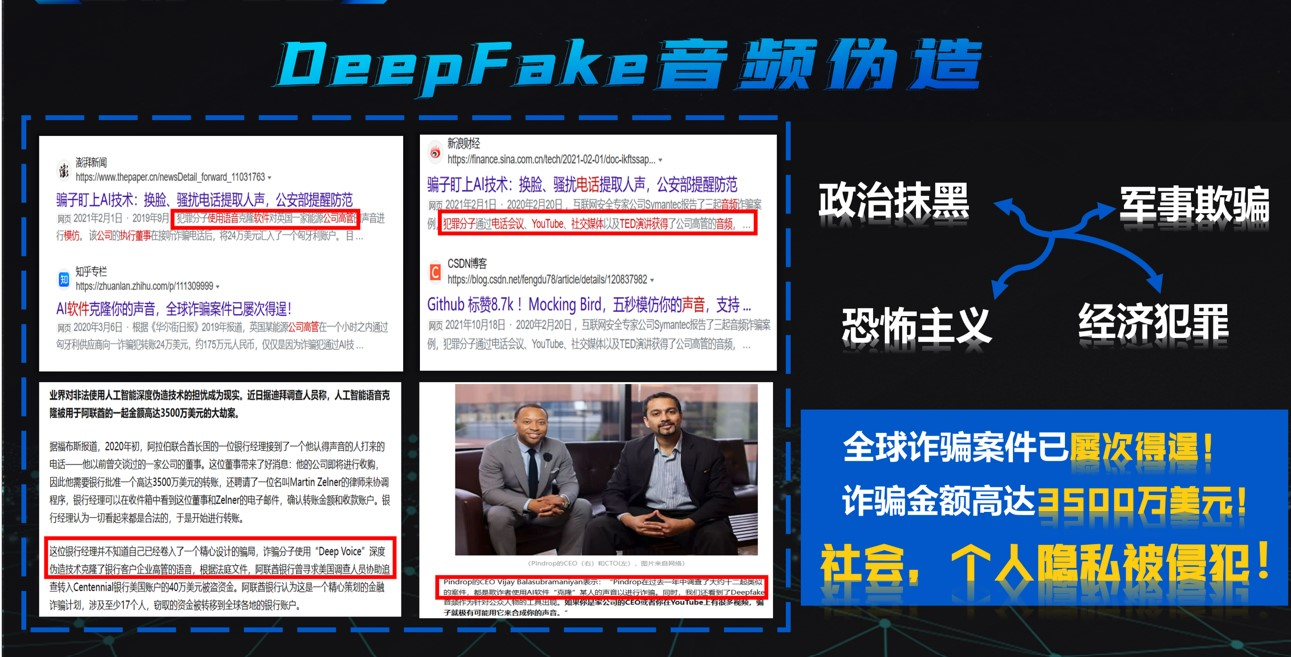
随着深度学习技术的应用,语音伪造技术飞速发展,最先进的语音合成、语音转换、语音重放等技术可以生成在人类听觉系统感知上与人类真实语音难以区分的伪造语音。然而,语音伪造技术一旦被不法分子利用,如应用于舆论误导或攻击身份识别系统等不良用途,将会对全球的民生、经济、政治和社会带来严重的威胁。深度伪造音频检测技术(Deepfake Audio Detection Technology)是一种用于检测和识别经过技术篡改音频文件的技术。该检测技术的研究对个人隐私的保护和社会信任体系的维护都有着极其重要的意义。
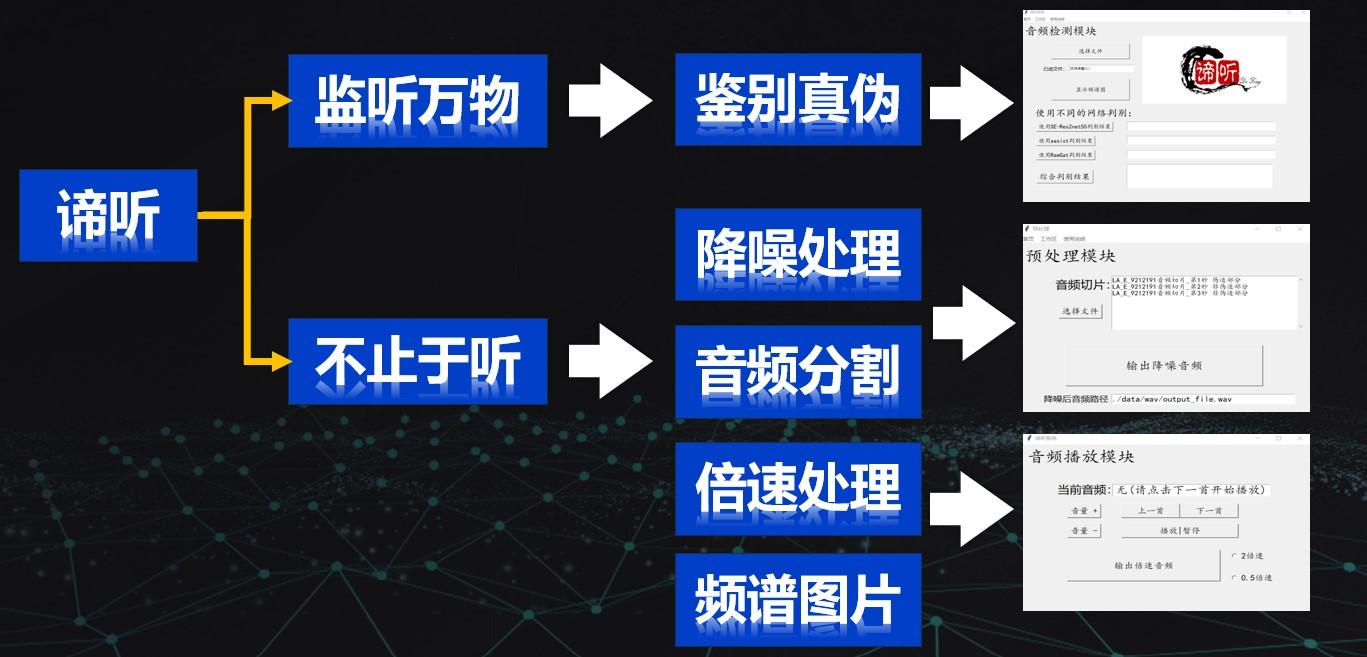
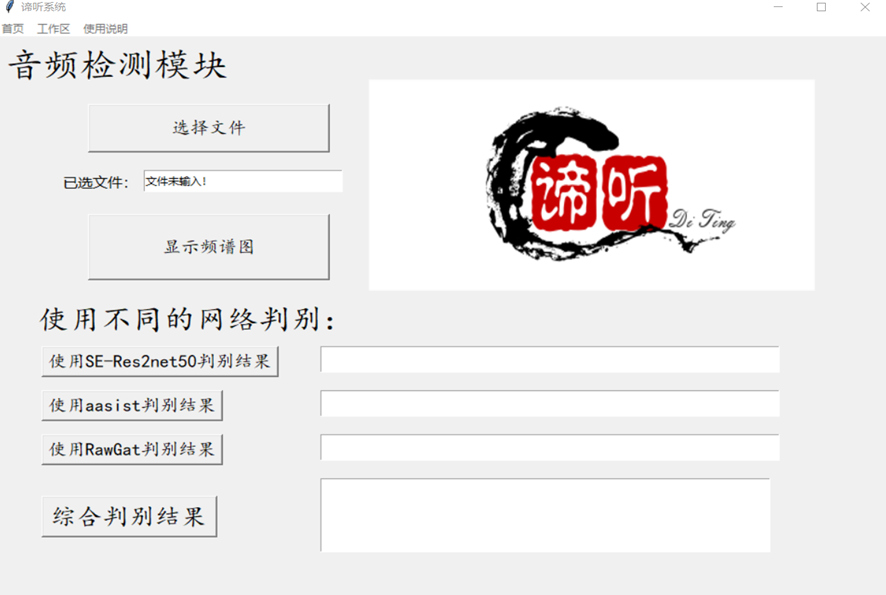
目前市面上部分伪造音频检测软件使用一种deepfake深度检测网络作为内部核心,其鉴别真伪能力明显不足以应对日渐成熟且变化莫测的音频伪造技术。谛听小队针对这个问题,设计实现了一个集成RawGAT-ST-antispoofing、AA-SIST、SE-Res2Net等三种检测网络对音频进行深度伪造检测与综合处理的原型系统。

他们通过三种网络同时分析待检测音频,使用投票集成法,对三种网络的结果进行综合分析处理,旨在进一步加强对假冒攻击、伪装欺骗两种典型伪造行为的检测效果。其原型系统在ASVspoof2019的LA数据集上进行训练并达到了0.063%的EER,1.96%的t-DCF的判别准确度。
谛听小队使用Python语言进行GUI界面的制作,同时使用音频切片检测的方案,可以明确音频中被伪造的片段,而不是粗略地对整个音频进行定性判断,提高检测精度,最终生成完备的结果分析报告,协助用户进行分析判断。另外,在实现音频伪造检测功能的基础上,他们还增加了对音频进行综合处理的模块,包括倍速,降噪等功能。